M04A Conjugate Gradient Method in MD++
Manual 04A for MD++
Conjugate Gradient Method in MD++
Keonwook Kang and Wei Cai
Conjugate Gradient Method
The conjugate gradient (CG) method was initially proposed as an iterative method to solve a large linear system of equations,[1] such as Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle \mathrm{A}\mathbf{x} = \mathbf{b}} , where A is an n by n symmetric (positive-definite) matrix, and b is an n by 1 vector. The basic idea is that the quadratic form of a function Ψ(x),
| Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle \Psi(\mathbf{x}) = \frac{1}{2}\mathbf{x}^T \mathrm{A}\mathbf{x} - \mathbf{b}^T\mathbf{x} + c} |
is minimized by the solution of Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle \mathrm{A}\mathbf{x} = \mathbf{b}} if A is symmetric and positive-definite. Later, Fletcher and Reeves[2] adopted it to solve nonlinear optimization problems. In MD++, the CG method is used to find a meta-stable structure by minimizing a given (usu. nonlinear) potential energy function.
The algorithm of the CG method is structured by two nested loops. The outer loop tries different search directions, and the inner loop aims to find the optimal step length which minimizes the object function along a given search direction. The inner loop may not be needed when the exact expression of the optimal step length can be given. If a certain condition is met, the program exits out of the loops and stops. The algorithm is shown in figure 1.

In figure 1, Ψ(x) is a function to be minimized, g is the gradient of Ψ, and s is the search direction. αk is the optimal step length that minimizes the function Ψ(xk+αksk) at the k-th iteration. βk+1 is the parameter related with update of the search direction.
Depending on how we choose β, the minimization methods can be different. For example, if βk=0, it is the steepest descent (SD) method.
While there exists the analytical expression of α for a linear system, or
| Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle \alpha_k=\Bigg\{} | for SD,[3] | |
| for CG, |


where rk is the residual and is defined as , for nonlinear problems, α is generally obtained by a numerical method such as Newton's method, quasi-Newton method, secant method, interpolation method, or other similiar methods. These methods of finding an optimal α are called as the line search methods. For details of the line search method, refer Nocedal and Wright's Numerial Optimization[4]

For the CG method, the search directions are constructed by using the conjugacy of the residuals, or
| for . |


From this condition, βk is obtained as
| . |

For details of the derivation, refer J. R. Shewchuk's.[5] The benefit of this choice is that a new search direction is orthogonal to all the previous search directions. In other words, we don't need to store all the previous search directions to produce a linearly independent new search direction.
Non-linear CG method
For non-linear CG method, there exist different choices of β as shown in table 1, in which the residual rk is now defined as the negative gradient or .

| Name | Reference | Features | |
|---|---|---|---|
| HS | Cite error: Closing </ref> missing for <ref> tag |
Hestenes and Stiefel (1952) | |
| FR | Fletcher and Reeves (1964) | Considered as the 1st non-linear CG method. Same with β in linear CG. Jamming problem[7] | |
| PR | Polak and Ribiere (1969), and Polyak (1969) | If an object function Ψ is strongly convex quadratic and the line search is exact, βPR = βFR because riTrj=0 for . Can avoid jamming problem by effectively restarting CG with . [8] | |
| PR+ | Powell (1984)[9] | Convergence guaranteed. Restart CG if βk+1<0. Restarting CG means that all the previous search directions are to be forgotten and the new search direction is set to be the steepest descent direction. | |
| HS+ |







Hybrid method
For better performance, people may use a hybrid method, which can select different β at each iteration. One example of hybrid methods is PR-FR method, in which method β is selected as

Stopping conditions
Below are listed the conditions to be used for stopping the CG program. You can terminate the CG routine if any one of the conditions is satisfied.
- Energy criterion
- Exit the loop if the following inequality holds for a given energy tolerance, Etol, which is in no unit.
- Force criterion (ftol)
- Exit the loop if the following inequality holds for a given force tolerance, ftol (eV/Å).
- Max. evaluations
- Exit the loop if the number of function-evaluation exceeds the maximum calling number, maxcall.
- Max. iterations
- The loop will finish if the iteration number reaches the maximum value, maxiter.


Conditions 1 to 3 may also be checked inside the inner loop for earlier exit and CG termination. Other condtions to be checked are
- the new search direction is uphill (sk+1Tgk+1 >= 0) or downhill (sk+1Tgk+1 < 0), and
- the step size α is zero or not.
If the new search direction is uphill, the search direction is set to be a steepest descent direction. If the step size α is zero, then stop the CG algorithm.
Implementation of the CG method in MD++
MD++ is equipped with two different CG methods. One is what we call as zxcgr and the other is PR+. Details of each method will be explained below.
zxcgr
zxcgr code was a part of IMSL(International Mathematics and Statistics Library)'s U2CGG.F. It was reimplemented into C to be used in MD++. This code follows Powell's restart procedures for the CG method.[10] According to his paper, the search direction is updated as
| , |

where and the extra term is related with how we restart CG. If we need to restart CG at k-th iteration, we set t = k - 1 and λk = 0. Then the restarting direction simply becomes sk = -gk + βksk-1. After restarting CG, λk is defined as



where t is the iteration number that is one time earlier than the iteration number at which restarting happened. Thus, λk can be summarized as

The initial value of t is zero and will not change until the 1st restart occurs. Naturally, you would think of what the restarting conditions are. One condition is that a new gradient gk+1 loses enough orthogonality with the previous gradient gk. In other words, the quantities gkTgk+1 and gk+1Tgk+1 become comparable. If the inequality

holds, restart CG. The other condition is that a new search direction is not sufficiently downhill. As the search direction gets closer to the steepest descent direction or -gk+1, we can say the direction becomes more downhill. So, we can propose an inequality

for the sufficient downhill condition. If this condition is not met, restart CG. The sufficient downhill condition can be rewritten as
| Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle |\beta_{k+1}(\mathbf{s}_k^T\mathbf{g}_{k+1}) + \lambda_{k+1}(\mathbf{s}_t^T\mathbf{g}_{k+1})| \leq 0.2\|\mathbf{g}_{k+1}\|^2 } |
using the relation for the search direction update. There is one more restarting condition, Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle (k-t) \geq n} , where n is the number of degree of freedom of the system. This condition is rarely used in atomistic simulations because n is usually very huge.
Unlike the other CG methods, this variation of CG method provides a restarting direction that is not a steepest descent direction. This modification usually takes less iterations to get to the minimum.
The Line Search Method in zxcgr
Since the search direction is downhill when the line search starts, there are only three possible cases shown below.
- Figure 2
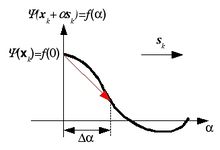
(a) Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle f(\Delta\alpha)<f(0)} and Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle f'(\Delta\alpha)f'(0)>0}
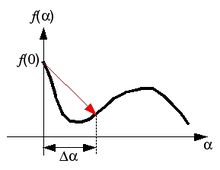
(b) Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle f(\Delta\alpha)<f(0)} and Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle f'(\Delta\alpha)f'(0)<0}
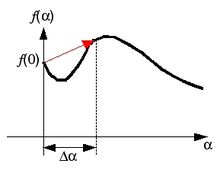
(c) Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle f(\Delta\alpha)>f(0)}



In case (a), keep searching the optimal α in the same direction. you may increase the step size for fast search. In case (c), reduce the step size by half, and perform the next search. In case (b), interpolate f(α) with the quadratic spline and set αk that minimizes the spline. Note that the slope of a function f(α), df/dα corresponds to the dot product of the gradient vector at α with the search direction, or
| Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle \frac{df(\alpha)}{d\alpha} = \mathbf{s}_k^T\mathbf{g}(\mathbf{x}_k + \alpha\mathbf{s}_k)} . |
In zxcgr, the maximum iteration number for the line search is set as MAXLIN = 5 in the relax_zxcgr.cpp file. If the line search cannot find an α that reduces the function f within 5 consecutive iterations, the following error message will be printed: "CGRelax: Line search aborted"
PR+
PR+ routine was added by Keonwook Kang in 2009 based on LAMMPS's min_cg.cpp file. The update parameter is βPR+. For the line search method, the backtracking method[11] is used. The backtracking method does not guarantee that a function f minimizes at the obtained α. This method allows any step size that can sufficiently decrease the function f. This decision can be justified if it is undesirable or impossible to exactly minimizes a function f or if we do not want to spend too much computation time to find an exact α.
Comparision of the CG methods in different implementation
In the first part of this section, I compare the computation results obtained from CG relxation between MD++ (ver.Mar202009) and LAMMPS (ver.Mar262009). The test system is a 3[100] x 3[010] x 3[001] Si diamond cubic structure stretched by 10% in all three directions with two missing atoms (of atom ID 0 and 99). The number of atoms in the test system is 8x33 - 2 = 214. The potential fuction is MEAM Siz with the cut-off radius rc=6(Å). The CG method is implemented by using the Polak-Ribiere method (PR+) and the backtracking method. The energy and the force tolerances are given as etol = 1e-6 (no unit) and ftol = 1e-8 (eV/Å), respectively. In the 1st column of table 2, the potential energies of the perfect structure from MD++ and LAMMPS are compared, and they are identical. In the 2nd column, the potential energies of the defect structure before relaxation are compared, and they are again same. In the 4th column, the energies of the relaxed structure are listed in different colors depending on the values of dmax (0.1, 0.01, and 0.001), which are related with the initial step length, and we can say that the both results are effectively identical. For this small test system, MD++ is faster than LAMMPS, because of less evaluation of the potential function. For a larger system, LAMMPS can perform better due to its ability of parallel run.
| Eperf (eV) | Edefect (eV) | dmax (Å) | Erlx (eV) | Iter. No. | No. of Calls | CPU time | |
|---|---|---|---|---|---|---|---|
| MD++ (PR+) | -1.00008000022397e+03 | -9.00066105589930e+02 | 0.1 | -9.04000029718829e+02 | 15 | 46 | 0.30002 |
| 0.01 | -9.04000167032814e+02 | 46 | 51 | 0.33202 | |||
| 0.001 | -9.03987772936424e+02 | 424 | 425 | 2.2201 | |||
| LAMMPS (Serial Run) | -1.00008000022397e+03 | -9.00066105589930e+02 | 0.1 | -9.04000029718830e+02 | 15 | 60 | 0.75296 |
| 0.01 | -9.04000167032815e+02 | 46 | 96 | 1.2149 | |||
| 0.001 | -9.03987772936423e+02 | 424 | 848 | 10.281 |
The distinct difference of the CG method between MD++ and LAMMPS lies in the fact that MD++ runs the CG method in scaled coordinate (x*) while LAMMPS does in real coordinate (x). Because of this scaling effect, dmax must be devided by the box length L for MD++, or d*max = dmax/L. By the same reason, the force tolerance in MD++ needs to be multiplied by the box length, or ftol* = L·ftol.
Now, I compare zxcgr and PR+ in MD++. Since it is only the force tolerance that the "zxcgr" code considers to check the convergence, the energy tolerance will be set to be 0 in the comparison below. In table 3, the numbers are same upto 1e-8. Note that the energy obtained by the PR+ method becomes lower than the number (in table 2) from the same method with nonzero etol (=1e-6). This further relaxation can be understood, if we consider that in the case of nonzero energy tolerance a small step makes the energy change small enough to satisfy the energy tolerance and the system is prone to stop relaxing further even though it is able to do because of its nonzero gradient (or force).
| dmax (Å) | Erlx (eV) | Iter. No. | No. of Calls | CPU time | |
|---|---|---|---|---|---|
| MD++ (zxcgr) | -9.04000245866814e+02 | 31 | 45 | 0.31602 | |
| MD++ (PR+) | 0.1 | -9.04000245866095e+02 | 35 | 124 | 0.70004 |
| 0.01 | -9.04000245869413e+02 | 63 | 117 | 0.70004 | |
| 0.001 | -9.04000245869795e+02 | 460 | 483 | 2.6002 |
At this point, we may raise a question. Does the scaling effect ever affect the relaxation of a structure in a non-cubic cell? Let's say that we have a 6[100] x 3[010] x 3[001] Si diamond cubic structure stretched by 20% in x direction with two missing atoms (of atom ID 0 and 99). The relaxation results are listed in table 4 below.
| Eperf (eV) | Edefect (eV) | Erlx (eV) | Iter. No. | No. of Calls | |
|---|---|---|---|---|---|
| MD++ (zxcgr) | -2.00016000044795e+03 | -1.86579478735442e+03 | -1.86764046397026e+03 | 129 | 175 |
| MD++ (PR+) | -1.86764046392565e+03 | 168 | 686 | ||
| LAMMPS | -2.00016000044795e+03 | -1.86579478735442e+03 | -1.86764046393067e+03 | 74 | 387 |
The relaxed energy values are same upto 1e-6.
Issues with a structure of multiple local minima
If a structure has multiple local minima that are closely located, can we get the same relaxed structure with different CG methods? A Si slab can easily have multiple metastable structures because of the surface reconstruction and for that reason it is a good test system for our purpose. The simulation systems are 5[100]x5[010]x2[001] Si slabs: one with a surface atom of ID 142 intentionally removed and the other with not. (See figure 3.) Both systems are relaxed with zxcgr and PR+ CG methods, and the results are summarized in table 5.
The Si slab with no atom removed was able to reach the same metastable structure regardless of CG methods. However, in the other slab the removed atom triggered the surface atoms' bonding or de-bonding differently depending on the CG method. Apparently, we observe two different surface reconstruction patterns obtained from the same initial structure.
| CG | System 1 (No atom removed) | System 2 (1 atom removed) | ||||
|---|---|---|---|---|---|---|
| Iter. No. | No. of Calls | Erlx (eV) | Iter. No. | No. of Calls | Erlx (eV) | |
| zxcgr | 13 | 29 | -1.69159677459827e+03 | 189 | 328 | -1.72478726205782e+03 |
| PR+ | 44 | 183 | -1.69159677459797e+03 | 571 | 1255 | -1.72304961624534e+03 |
| Initial structure of System 1 | Initial structure of System 2 | Relaxed structure of System 2 | ||
|---|---|---|---|---|
| zxcgr | PR+ | |||
| top view | 
|

|

|

|
| side view | 
|

|

|

|
How do we interprete this behavior? If a given object function has multiple local minima that are very close, a slightly different search path can lead you different energy valleys. This idea can be confirmed by relaxing structures with another Si potential, Stillinger-Weber (SW), which is less bumpy than MEAM. The relaxation results are shown below in table 6 and figure 4. According to the results, both zxcgr and PR+ methods give the same relaxed structure of the system 2 in terms of energy and the surface pattern. Note that the relaxed structures do not show any appreciable surface reconstruction.
| CG | System 1 (No atom removed) | System 2 (1 atom removed) | ||||
|---|---|---|---|---|---|---|
| Iter. No. | No. of Calls | Erlx (eV) | Iter. No. | No. of Calls | Erlx (eV) | |
| zxcgr | 6 | 10 | -1.62049999855975e+03 | 7 | 11 | -1.61586999856701e+03 |
| PR+ | 7 | 37 | -1.62049999855992e+03 | 7 | 37 | -1.61586999856631e+03 |
| Relaxed structure of System 2 | ||
|---|---|---|
| zxcgr | PR+ | |
| top view | 
|

|
| side view | 
|

|
This comparison does not mean that SW potential performs better than MEAM or the other way around. We just want to point out that there is a feature of a potential function that may unintendedly affect the relaxation results, and we have to be very careful when taking them.
Notes
- ↑ M. R. Hestenes and E. Stiefel, "Methods of conjugate gradients for solving linear systems", Journal of Research of the National Bureau of Standards, 49(1952) pp.409-436
- ↑ R. Fletcher and C. M. Reeves, "Function minimization by conjugate gradients", Computer Journal, 7(1964) pp.149-154
- ↑ This expression can be obtained by using two consecutive gradients are orthogonal, or gTk+1gk=0. In this case, we don't need the inner loop.
- ↑ Jorge Nocedal and Stephen J. Wright, Numerical Optimization 2nd ed. Springer (2006)
- ↑ J. R. Shewchuk, An Introduction to the Conjugate Gradient Method Without the Agonizing Pain (1994)
- ↑ W. W. Hager and H. Zhang, "A survey of nonlinear conjugate gradient methods", Pacific J. of Optimization, 2(2006) pp.35-58
- ↑ While you minimize a general object function, you may have a bad search direction, which is almost orthogonal to the steepest descent direction, -gk. Once you have a bad direction, the FR method is likely to give you a next search direction close to the previous direction, or Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle \mathbf{s}_{k+1}\sim \mathbf{s}_{k}} , which is another bad direction. See Nocedal and Wright pp. 125 - 127 Behavior of the Fletcher-Reeves Method
- ↑ When a search direction is almost orthogonal to the steepest descent direction, βPR becomes almost zero (Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "https://wikimedia.org/api/rest_v1/":): {\displaystyle \beta \sim 0} ) and the search direction is close to the steepest descent direction.
- ↑ M. J. D. Powell, "Nonconvex minimization calculations and the conjugate gradient method", Numerical Ananlysis (Dundee, 1983), Lecture Notes in Mathematics, vol. 1066, Springer-Verlag, Berlin, 1984 pp.122-141
- ↑ M. J. D. Powell, "Restart Procedures for the Conjugate Gradient Method", Mathematical Programming 12 (1977) pp.241-254
- ↑ Nocedal and Wright, "Numerical Optimization" ch.3.1 pp.37 sufficient decrease and backtracking